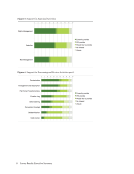
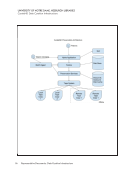
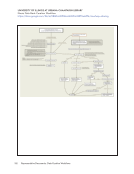
58 Survey Results: Survey Questions and Responses
ADDITIONAL COMMENTS
42. Please enter any additional information regarding data curation practices at your institution that
may assist the authors in accurately analyzing the results of this survey. N=34
Currently provide data curation services N=20
2012–2016 we were using Hydra/Fedora as a data repository. Starting in March 2016, we moved to local
installation of Dataverse.
Data curation is not centralized, and the institution is currently reviewing policy with respect to
research datasets. There are multiple sites of data curation within the university, this survey response
has attempted to capture those from the University Library System and the Health Sciences Library
System, but does include other centers and units.
Due to our small staff size we focus on automated data curation workflow development to achieve
efficiencies for ingesting large collections of data. We are currently in the process of establishing the
necessary relationships with campus IT and the Office of the Vice President for Research to address
scalability and outreach needs. Significant organizational turnover in IT, OVPR, and library IT have
also posed challenges to establishing scalable systems in support of data curation.
I have a growing sense that our community’s data curation programs are neither here nor there. That
is, attempts to curate data with a high degree of interaction with researchers (e.g., for preservation
purposes) have resulted in low amounts of data deposit. Most researchers do not understand the
need for such effort. Alternately, strategies that result in greater data deposit may be compromising
the ability to preserve data in the future (with “future” being defined as little as five years). Much
of our data curation activity relates to compliance with funding agency guidelines or requirements.
Is this resulting in a coordinated, intentional collection effort? Is it resulting in better research?
Reproducibility of research? Are libraries providing data curation for the large reference collections of
data? Regardless of your political view, the reality is that many researchers are currently exerting effort
to safeguard, transfer, migrate, etc. their data given the current political climate. How many of them
are reaching out to ARL libraries for help? If the answer is not many—or even none—shouldn’t we ask
ourselves why?
More on the “above campus” activity: consortial and commercial arrangements that impact policy and
procedural developments.
Most of our current/to date support for data curation comes in the form of consultations for DMPs. We
do have more robust data curation for our special collections. We do not have a data repository at this
time. Should this situation change, we would embark on more data curation activities.
NARA is a federal agency responsible for preserving and providing access to electronic records
scheduled for permanent retention in the National Archives. Our legislative mandate and supporting
regulations and guidance require federal agencies to transfer records in regular intervals, in acceptable
formats, and with adequate documentation and metadata.
One of the challenges is being able to re-allocate resources to data curation when new funding is not
available. Mandates for depositing research data are not very strong yet in Canada, and demand for data
curation services is not always high enough to drive funding. UBC is one of the leaders of Portage, a
Canadian, library-based research data management network that coalesces initiatives in research data
management to build capacity and to coordinate activities (https://portagenetwork.ca/about/).
Our Data Coordinating Center provides many of these services, however, they are part of our CTSI
and the library is currently developing a relationship with them (thus it is hard to provide exact
ADDITIONAL COMMENTS
42. Please enter any additional information regarding data curation practices at your institution that
may assist the authors in accurately analyzing the results of this survey. N=34
Currently provide data curation services N=20
2012–2016 we were using Hydra/Fedora as a data repository. Starting in March 2016, we moved to local
installation of Dataverse.
Data curation is not centralized, and the institution is currently reviewing policy with respect to
research datasets. There are multiple sites of data curation within the university, this survey response
has attempted to capture those from the University Library System and the Health Sciences Library
System, but does include other centers and units.
Due to our small staff size we focus on automated data curation workflow development to achieve
efficiencies for ingesting large collections of data. We are currently in the process of establishing the
necessary relationships with campus IT and the Office of the Vice President for Research to address
scalability and outreach needs. Significant organizational turnover in IT, OVPR, and library IT have
also posed challenges to establishing scalable systems in support of data curation.
I have a growing sense that our community’s data curation programs are neither here nor there. That
is, attempts to curate data with a high degree of interaction with researchers (e.g., for preservation
purposes) have resulted in low amounts of data deposit. Most researchers do not understand the
need for such effort. Alternately, strategies that result in greater data deposit may be compromising
the ability to preserve data in the future (with “future” being defined as little as five years). Much
of our data curation activity relates to compliance with funding agency guidelines or requirements.
Is this resulting in a coordinated, intentional collection effort? Is it resulting in better research?
Reproducibility of research? Are libraries providing data curation for the large reference collections of
data? Regardless of your political view, the reality is that many researchers are currently exerting effort
to safeguard, transfer, migrate, etc. their data given the current political climate. How many of them
are reaching out to ARL libraries for help? If the answer is not many—or even none—shouldn’t we ask
ourselves why?
More on the “above campus” activity: consortial and commercial arrangements that impact policy and
procedural developments.
Most of our current/to date support for data curation comes in the form of consultations for DMPs. We
do have more robust data curation for our special collections. We do not have a data repository at this
time. Should this situation change, we would embark on more data curation activities.
NARA is a federal agency responsible for preserving and providing access to electronic records
scheduled for permanent retention in the National Archives. Our legislative mandate and supporting
regulations and guidance require federal agencies to transfer records in regular intervals, in acceptable
formats, and with adequate documentation and metadata.
One of the challenges is being able to re-allocate resources to data curation when new funding is not
available. Mandates for depositing research data are not very strong yet in Canada, and demand for data
curation services is not always high enough to drive funding. UBC is one of the leaders of Portage, a
Canadian, library-based research data management network that coalesces initiatives in research data
management to build capacity and to coordinate activities (https://portagenetwork.ca/about/).
Our Data Coordinating Center provides many of these services, however, they are part of our CTSI
and the library is currently developing a relationship with them (thus it is hard to provide exact