3 SPEC Kit 354: Data Curation
of sharing and subsequent reuse is predicated on dataset quality, which is difficult to achieve without
appropriate curation.
The purpose of this survey was to uncover the current staffing and infrastructure (policy and
technical) at ARL member institutions for data curation, understand the current level of demand for data
curation services, and discover any challenges that institutions are currently facing regarding providing
data curation services. The survey was distributed to the 124 ARL member libraries in January 2017.
Eighty (65%) responded by the January 30 deadline.
Current State of Curation Services
The survey results show that a majority of ARL libraries are providing data curation services or that
development of these services is underway. Specifically, of the 80 survey respondents, 51 (nearly two
thirds) indicated that they are currently providing services to support data curation and another 13
indicated that they are developing these services. Only 20% of the sample, or 16 libraries, indicated that
they do not provide nor are actively developing data curation services. Data curation services appear to
be a relatively recent initiative more than half of the libraries that currently provide services (35 of 51)
started doing so in 2010 or later.
Looking closer at the 51 institutions that provide data curation services, most (46 or 90%) also
provide repository services for data. Twenty-nine have an institutional repository that accepts data. A
smaller number (8 or 17%) have a stand-alone data repository. Similar to the responses on data curation
services, the majority of these repositories came online in 2010 or later. DSpace is the most common
repository platform and is used by 22 of the reporting institutions. Eleven use Dataverse (as either a
hosted or a local installation), 10 use Fedora/Hydra, and seven use Islandora. Seventeen respondents use
a combination of these or other platforms.
Interest in providing data curation services does not yet appear to have translated into strong
staff levels to provide these services. The survey asked how many staff focus 100% of their time and how
many spend part of their time on data curation services. The responses show that the majority of libraries
place responsibility for data curation services on individuals who have other duties to carry out.
Forty-nine responding libraries reported a total of 293 staff who are involved in data curation
activities. Forty-five of these reported they have staff who focus part of their time on data curation (a total
of 231 individuals). The number of partial focus staff ranges from one to 15 per library. The percentage of
time they spend varies widely by institution, with some reporting 5–10% of time and others indicating it
may be as high as 40–50%. (See question 4 for specifics.) Some institutions stated that the amount of staff
time spent is variable depending on demand from researchers.
Twenty-eight respondents only have partial focus staff (a total of 143 individuals). Seventeen
have both partial focus and exclusive focus staff (88 partial and 39 exclusive). Three libraries have one
person who spends all their time on data curation. An outlier reported 20 staff devoted exclusively to
these activities.
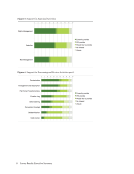
The 51 responses to a question on the source of demand for data curation services shows it
comes from researchers across subject domains. As shown in the graph below, researchers from the
life sciences and social sciences are most likely to ask for these services (33 responses each or 65%).
Perhaps somewhat surprisingly given the focus STEM disciplines often receive in discussing data, arts
&humanities edged out both engineering and applied sciences and the physical sciences (21, 20, and 19
responses respectively). These are followed by other science disciplines.
of sharing and subsequent reuse is predicated on dataset quality, which is difficult to achieve without
appropriate curation.
The purpose of this survey was to uncover the current staffing and infrastructure (policy and
technical) at ARL member institutions for data curation, understand the current level of demand for data
curation services, and discover any challenges that institutions are currently facing regarding providing
data curation services. The survey was distributed to the 124 ARL member libraries in January 2017.
Eighty (65%) responded by the January 30 deadline.
Current State of Curation Services
The survey results show that a majority of ARL libraries are providing data curation services or that
development of these services is underway. Specifically, of the 80 survey respondents, 51 (nearly two
thirds) indicated that they are currently providing services to support data curation and another 13
indicated that they are developing these services. Only 20% of the sample, or 16 libraries, indicated that
they do not provide nor are actively developing data curation services. Data curation services appear to
be a relatively recent initiative more than half of the libraries that currently provide services (35 of 51)
started doing so in 2010 or later.
Looking closer at the 51 institutions that provide data curation services, most (46 or 90%) also
provide repository services for data. Twenty-nine have an institutional repository that accepts data. A
smaller number (8 or 17%) have a stand-alone data repository. Similar to the responses on data curation
services, the majority of these repositories came online in 2010 or later. DSpace is the most common
repository platform and is used by 22 of the reporting institutions. Eleven use Dataverse (as either a
hosted or a local installation), 10 use Fedora/Hydra, and seven use Islandora. Seventeen respondents use
a combination of these or other platforms.
Interest in providing data curation services does not yet appear to have translated into strong
staff levels to provide these services. The survey asked how many staff focus 100% of their time and how
many spend part of their time on data curation services. The responses show that the majority of libraries
place responsibility for data curation services on individuals who have other duties to carry out.
Forty-nine responding libraries reported a total of 293 staff who are involved in data curation
activities. Forty-five of these reported they have staff who focus part of their time on data curation (a total
of 231 individuals). The number of partial focus staff ranges from one to 15 per library. The percentage of
time they spend varies widely by institution, with some reporting 5–10% of time and others indicating it
may be as high as 40–50%. (See question 4 for specifics.) Some institutions stated that the amount of staff
time spent is variable depending on demand from researchers.
Twenty-eight respondents only have partial focus staff (a total of 143 individuals). Seventeen
have both partial focus and exclusive focus staff (88 partial and 39 exclusive). Three libraries have one
person who spends all their time on data curation. An outlier reported 20 staff devoted exclusively to
these activities.
The 51 responses to a question on the source of demand for data curation services shows it
comes from researchers across subject domains. As shown in the graph below, researchers from the
life sciences and social sciences are most likely to ask for these services (33 responses each or 65%).
Perhaps somewhat surprisingly given the focus STEM disciplines often receive in discussing data, arts
&humanities edged out both engineering and applied sciences and the physical sciences (21, 20, and 19
responses respectively). These are followed by other science disciplines.