Document Details
SPEC Kit 354: Data Curation (May 2017)
Page
94
(
102
of
143
)
GO
94
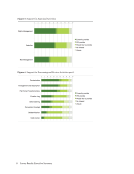
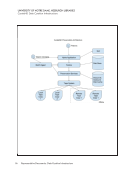
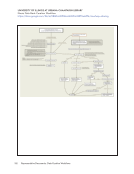
Representative
Documents:
Data
Curation
Infrastructure
Data
Curation
Infrastructure
Previous Page
Next Page
SPEC Kit 354: Data Curation (May 2017) resources
Download PDF
SPEC Kit 354 Data Curation (May 2017) (143)
Download PDF
Representative Documents (68)
Download PDF
Data Curation Infrastructure (6)
Help
Close
This book
Academic Health Library Statistics
Publications by Kozlowski, Wendy
Publications by Johnston, Lisa R.
Publications by Hudson-Vitale, Cynthia
Publications by Carlson, Jake
Publications by Imker, Heidi
Publications by Olendorf, Robert
Publications by Stewart, Claire
SPEC Kits
SPEC Kits ALL
Publications by Some Author
All books
GO
Zoom In
Zoom Out
Contents
Resources
Extract
Help
Printable
Destination page number
Search scope
Search Text