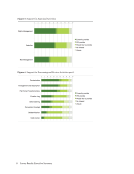
95 SPEC Kit 354: Data Curation
UNIVERSITY OF NOTRE DAME, HESBURGH LIBRARIES
CurateND Data Curation Infrastructure
CurateND Data Curation Infrastructure
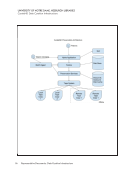
CurateND uses a Hydra-based discovery application. It uses Fedora Commons 3.x as the object
registry and metadata store and Apache Solr as an index. Using both Fedora and Solr is
common for Hydra applications. Self-deposit items go through the Hydra application. There is
also a batch ingest ability, which deposits items directly into the preservation store as well as
Fedora. Objects in Fedora contain pointers to our preservation store. The preservation store is a
custom application that puts content into BagIt bags for storage on tape; maintains a disk cache
of content; provides a URL for each preserved file; and runs fixity checks on the content. The
data is ultimately all stored on tape, with two copies kept locally and two remotely. The tape
appliance handles the replication.
Digital Librarians can deal with the batch ingest directly via a networked filesystem. Content is
staged on the filesystem, where it can also be reviewed, assessed, and described. When it is
ready, the librarian can start an ingest, which copies the data into the preservation system, the
metadata into the preservation system, and a copy of the metadata into Fedora. It then asks the
Hydra application to index the new content.
UNIVERSITY OF NOTRE DAME, HESBURGH LIBRARIES
CurateND Data Curation Infrastructure
CurateND Data Curation Infrastructure
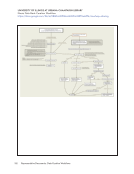
CurateND uses a Hydra-based discovery application. It uses Fedora Commons 3.x as the object
registry and metadata store and Apache Solr as an index. Using both Fedora and Solr is
common for Hydra applications. Self-deposit items go through the Hydra application. There is
also a batch ingest ability, which deposits items directly into the preservation store as well as
Fedora. Objects in Fedora contain pointers to our preservation store. The preservation store is a
custom application that puts content into BagIt bags for storage on tape; maintains a disk cache
of content; provides a URL for each preserved file; and runs fixity checks on the content. The
data is ultimately all stored on tape, with two copies kept locally and two remotely. The tape
appliance handles the replication.
Digital Librarians can deal with the batch ingest directly via a networked filesystem. Content is
staged on the filesystem, where it can also be reviewed, assessed, and described. When it is
ready, the librarian can start an ingest, which copies the data into the preservation system, the
metadata into the preservation system, and a copy of the metadata into Fedora. It then asks the
Hydra application to index the new content.