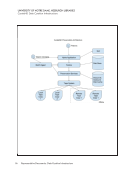
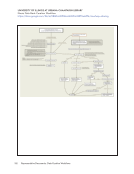
46 Survey Results: Survey Questions and Responses
Peer-review: Dataverse provides support for anonymous review of data sets. Transcoding is done as
needed by a unit outside of Data Curation.
Some of these activities (file renaming, restructure) happen at initial ingest but there is no
periodic review.
Some of these are supported via training, not directly by work performed by library staff.
Studies are currently underway to address these data curation issues.
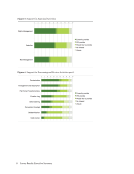
These ten activities are the most difficult to implement because they are the most time consuming
and resource intensive. These activities also require a high degree of both technical training and
disciplinary knowledge. We are slowly working towards supporting these activities, however, some,
like peer-review, are and will continue to be out of reach. If depositors/users supply us with this
metadata, and/or ask us for assistance, then we will provide this support where possible. However, we
cannot currently provide large-scale support across all datasets deposited in our repository.
We archive software locally only if it is provided with the data by the researcher. We do, however, use
DROID to identify file formats and record the PUID in order to use the PRONOM registry to monitor
and mitigate software and format obsolescence. If you consider this approach to fit the criteria of a
software registry, I would change this line from ‘unsure’ to ‘currently providing’.
SUPPORT FOR ACCESS ACTIVITIES
Here are descriptions of eleven data curation access activities.
Contact Information: Keep up-to-date contact information for the data authors and/or the contact
persons in order to facilitate connection with third-party users. Often involves managing ephemeral
information that will change over time.
Data Citation: Display of a recommended bibliographic citation for a dataset to enable appropriate
attribution by third-party users in order to formally incorporate data reuse as part of the
scholarly ecosystem.
Data Visualization: The presentation of pictorial and/or graphical representations of a data set used
to identify patterns, detect errors, and/or demonstrate the extent of a data set to third party users.
Discovery Services: Services that incorporate machine-based search and retrieval functionality that
help users identify what data exist, where the data are located, and how can they be accessed (e.g.,
full-text indexing or web optimization).
Embargo: To restrict or mediate access to a data set, usually for a set period of time. In some cases an
embargo may be used to protect not only access, but any knowledge that the data exist.
File Download: Allow access to the data materials by authorized third parties.
Full-Text Indexing: Enhance the data for discovery purposes by generating search-engine-optimized
formats of the text inherent to the data.
Metadata Brokerage: Active dissemination of a data set’s metadata to search and discovery services
(e.g., article databases, catalogs, web-based indexes) for federated search and discovery.
Restricted Access: In order to maintain the privacy of research subjects without losing integral
components of the data, some data access will be protected and/or mediated to individuals that meet
predefined criteria.
Terms of Use: Information provided to end users of a data set that outline the requirements or
conditions for use (e.g., a Creative Commons License).
Peer-review: Dataverse provides support for anonymous review of data sets. Transcoding is done as
needed by a unit outside of Data Curation.
Some of these activities (file renaming, restructure) happen at initial ingest but there is no
periodic review.
Some of these are supported via training, not directly by work performed by library staff.
Studies are currently underway to address these data curation issues.
These ten activities are the most difficult to implement because they are the most time consuming
and resource intensive. These activities also require a high degree of both technical training and
disciplinary knowledge. We are slowly working towards supporting these activities, however, some,
like peer-review, are and will continue to be out of reach. If depositors/users supply us with this
metadata, and/or ask us for assistance, then we will provide this support where possible. However, we
cannot currently provide large-scale support across all datasets deposited in our repository.
We archive software locally only if it is provided with the data by the researcher. We do, however, use
DROID to identify file formats and record the PUID in order to use the PRONOM registry to monitor
and mitigate software and format obsolescence. If you consider this approach to fit the criteria of a
software registry, I would change this line from ‘unsure’ to ‘currently providing’.
SUPPORT FOR ACCESS ACTIVITIES
Here are descriptions of eleven data curation access activities.
Contact Information: Keep up-to-date contact information for the data authors and/or the contact
persons in order to facilitate connection with third-party users. Often involves managing ephemeral
information that will change over time.
Data Citation: Display of a recommended bibliographic citation for a dataset to enable appropriate
attribution by third-party users in order to formally incorporate data reuse as part of the
scholarly ecosystem.
Data Visualization: The presentation of pictorial and/or graphical representations of a data set used
to identify patterns, detect errors, and/or demonstrate the extent of a data set to third party users.
Discovery Services: Services that incorporate machine-based search and retrieval functionality that
help users identify what data exist, where the data are located, and how can they be accessed (e.g.,
full-text indexing or web optimization).
Embargo: To restrict or mediate access to a data set, usually for a set period of time. In some cases an
embargo may be used to protect not only access, but any knowledge that the data exist.
File Download: Allow access to the data materials by authorized third parties.
Full-Text Indexing: Enhance the data for discovery purposes by generating search-engine-optimized
formats of the text inherent to the data.
Metadata Brokerage: Active dissemination of a data set’s metadata to search and discovery services
(e.g., article databases, catalogs, web-based indexes) for federated search and discovery.
Restricted Access: In order to maintain the privacy of research subjects without losing integral
components of the data, some data access will be protected and/or mediated to individuals that meet
predefined criteria.
Terms of Use: Information provided to end users of a data set that outline the requirements or
conditions for use (e.g., a Creative Commons License).