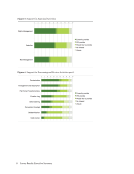
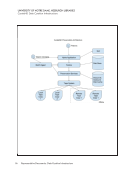
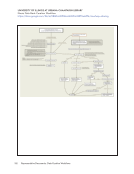
44 Survey Results: Survey Questions and Responses
Comments N=15
Code review is on a case-by-case basis if we have the expertise. Conversion from analog comes up
with archival material or lab notebooks, we scan but so far do not convert to machine-actionable,
Deidentification is something we want to do but need partners on campus.
Dataverse automatically converts well-formed Excel spreadsheets to .csv.
For deidentification, it’s unlikely we will perform the service directly given potential legal, compliance,
etc. issues. We do provide training for both data managers and researchers about best practices and
possible tools for deidentification.
For file format transformations, we can handle only the basic, as in MS Office formats to open formats.
We cannot handle at this time formats such as R or that are from specific machines and must use those
machines to run the code.
In some instances, we do undertake making corrections to the data, however, the quality of the data
remains the responsibility of the depositor.
Most of the above is particularly for libraries collections.
Most of these services are provided ad-hoc. We will provide them when requested, however, we do not
yet have an established service for data sets. Additionally, our Data Coordinating Center provides a lot
of these services on the medical campus.
Multiple internal studies are currently underway looking at support for these data curation issues.
Note that some of these services are provided as needed and are not necessarily automated or
integrated into a system.
Reluctantly toggled for “code review”: we’ve done related HTML review for “research-based websites”
that we’ve acquired, cleaned/modified, and otherwise curated.
Some conversion may occur through our digital collections unit if the collection is unique however, this
is more common for cultural heritage materials than research datasets.
Some of these processes are supported by training, but not performed by library staff.
Staff limitations contribute to the “3” responses above.
There can be significant costs associated with the reprocessing of information. At this time, that is not
a cost the libraries are willing to accept. However, that does not mean that as new formats are adopted
that there would be an associated method that would be made available for the individual wanting the
data could use as a roadmap.
We might do some of these things if our library selects a dataset to preserve forever (Nobel Prize
winner’s lab notebooks), or if a researcher provided grant funding for library staff involvement.
SUPPORT FOR PROCESSING AND REVIEW ACTIVITIES PART 2
Here are descriptions of ten more data curation processing and review activities.
File Inventory or Manifest: The data files are inspected periodically and the number, file types
(extensions), and file sizes of the data are understood and documented. Any missing, duplicate, or
corrupt (e.g., unable to open) files are discovered.
File Renaming: To rename files in a dataset, often to standardize and/or reflect important metadata.
Indexing: Verify all metadata provided by the author and crosswalk to descriptive and administrative
metadata compliant with a standard format for repository interoperability.
Comments N=15
Code review is on a case-by-case basis if we have the expertise. Conversion from analog comes up
with archival material or lab notebooks, we scan but so far do not convert to machine-actionable,
Deidentification is something we want to do but need partners on campus.
Dataverse automatically converts well-formed Excel spreadsheets to .csv.
For deidentification, it’s unlikely we will perform the service directly given potential legal, compliance,
etc. issues. We do provide training for both data managers and researchers about best practices and
possible tools for deidentification.
For file format transformations, we can handle only the basic, as in MS Office formats to open formats.
We cannot handle at this time formats such as R or that are from specific machines and must use those
machines to run the code.
In some instances, we do undertake making corrections to the data, however, the quality of the data
remains the responsibility of the depositor.
Most of the above is particularly for libraries collections.
Most of these services are provided ad-hoc. We will provide them when requested, however, we do not
yet have an established service for data sets. Additionally, our Data Coordinating Center provides a lot
of these services on the medical campus.
Multiple internal studies are currently underway looking at support for these data curation issues.
Note that some of these services are provided as needed and are not necessarily automated or
integrated into a system.
Reluctantly toggled for “code review”: we’ve done related HTML review for “research-based websites”
that we’ve acquired, cleaned/modified, and otherwise curated.
Some conversion may occur through our digital collections unit if the collection is unique however, this
is more common for cultural heritage materials than research datasets.
Some of these processes are supported by training, but not performed by library staff.
Staff limitations contribute to the “3” responses above.
There can be significant costs associated with the reprocessing of information. At this time, that is not
a cost the libraries are willing to accept. However, that does not mean that as new formats are adopted
that there would be an associated method that would be made available for the individual wanting the
data could use as a roadmap.
We might do some of these things if our library selects a dataset to preserve forever (Nobel Prize
winner’s lab notebooks), or if a researcher provided grant funding for library staff involvement.
SUPPORT FOR PROCESSING AND REVIEW ACTIVITIES PART 2
Here are descriptions of ten more data curation processing and review activities.
File Inventory or Manifest: The data files are inspected periodically and the number, file types
(extensions), and file sizes of the data are understood and documented. Any missing, duplicate, or
corrupt (e.g., unable to open) files are discovered.
File Renaming: To rename files in a dataset, often to standardize and/or reflect important metadata.
Indexing: Verify all metadata provided by the author and crosswalk to descriptive and administrative
metadata compliant with a standard format for repository interoperability.