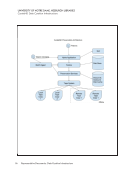
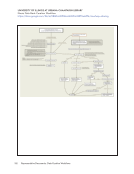
12 Survey Results: Executive Summary
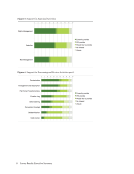
Providing a persistent identifier was ranked as the most important activity overall (with an
average ranking of 1.23). This is followed closely by metadata (1.25), information about terms of use
(1.35), allowing file download (1.39), having a deposit agreement from the author (1.5), documentation
that describes the data (1.5), a secure storage environment (1.52), a process for rights management (1.54),
discovery services for search and retrieval (1.61), and a data citation to enable appropriate attribution by
data users (1.65). Many of these highly ranked activities are commonly facilitated through institutional
repository platforms and software generally and are not unique to data.
On the other end of the scale, the curation activities that received the lowest rankings of
importance are mostly in the processing and review category. They include code review (with an average
ranking of 3.04), conversion of data to more usable formats (3.04), data cleaning (3.17), restructuring
poorly structured files (3.18), emulation to enable long-term usability of data (3.48), data visualization
(3.57), and least important, peer-review (3.91). Many of these lower ranked activities are more specialized
to data or are fairly complex in nature. The comments indicated that there are some questions about
whether these activities are the responsibility of libraries, the researcher who created the data, or of other
units on campus such as central IT. There were also comments questioning whether libraries possess
the infrastructure or the expertise needed to carry out these activities. Based on these responses it is not
clear that libraries have reached a consensus on a data curation definition and the role of the library in
providing research data curation services.
Limitations
Readers of this survey should be aware of its limitations. First, many of the comments indicated that
respondents conflated data curation activities with research data management services, and we regret
that we did not frame the distinction more explicitly for survey respondents. This indicates that a
common understanding of data curation is not widespread or ubiquitous. On the other hand, it also
illustrates an opportunity for increased education and outreach to the broader library community.
In a similar vein, many responses concerning library resources and repositories were answered
from the context of the greater organization. For instance, several respondents indicated they
concurrently use two to four repository platforms for data. However, closer examination of several of the
respondents’ websites revealed that some of the repositories do not house data or are actually affiliated
with other campus units. This may be a result of the survey design, it may suggest that many libraries do
not know where their data are going, or that they use several solutions, not all of them owned by their
unit, or both.
In many cases, the more quantitative questions, such as the number of FTEs devoted to data
curation, made it difficult to determine with precision the amount of effort libraries are expending on
data curation activities. Also, when querying the level of support provided by libraries (e.g., currently
providing or will provide in the near future, etc.), it appeared that responses were made relative to the
library’s overall resource pool. In other words, a small institution and a large institution might both have
responded at the same level of support, however, in absolute terms there may be a significant difference
between the two.
Additionally, analyzing the data and links provided by respondents to related resources indicates
that many institutions are providing curation activities only through their institutional repository, and are
therefore limited by its technical capabilities. However, other institutions provide additional curation and
review of the data files through staff-powered services.
Providing a persistent identifier was ranked as the most important activity overall (with an
average ranking of 1.23). This is followed closely by metadata (1.25), information about terms of use
(1.35), allowing file download (1.39), having a deposit agreement from the author (1.5), documentation
that describes the data (1.5), a secure storage environment (1.52), a process for rights management (1.54),
discovery services for search and retrieval (1.61), and a data citation to enable appropriate attribution by
data users (1.65). Many of these highly ranked activities are commonly facilitated through institutional
repository platforms and software generally and are not unique to data.
On the other end of the scale, the curation activities that received the lowest rankings of
importance are mostly in the processing and review category. They include code review (with an average
ranking of 3.04), conversion of data to more usable formats (3.04), data cleaning (3.17), restructuring
poorly structured files (3.18), emulation to enable long-term usability of data (3.48), data visualization
(3.57), and least important, peer-review (3.91). Many of these lower ranked activities are more specialized
to data or are fairly complex in nature. The comments indicated that there are some questions about
whether these activities are the responsibility of libraries, the researcher who created the data, or of other
units on campus such as central IT. There were also comments questioning whether libraries possess
the infrastructure or the expertise needed to carry out these activities. Based on these responses it is not
clear that libraries have reached a consensus on a data curation definition and the role of the library in
providing research data curation services.
Limitations
Readers of this survey should be aware of its limitations. First, many of the comments indicated that
respondents conflated data curation activities with research data management services, and we regret
that we did not frame the distinction more explicitly for survey respondents. This indicates that a
common understanding of data curation is not widespread or ubiquitous. On the other hand, it also
illustrates an opportunity for increased education and outreach to the broader library community.
In a similar vein, many responses concerning library resources and repositories were answered
from the context of the greater organization. For instance, several respondents indicated they
concurrently use two to four repository platforms for data. However, closer examination of several of the
respondents’ websites revealed that some of the repositories do not house data or are actually affiliated
with other campus units. This may be a result of the survey design, it may suggest that many libraries do
not know where their data are going, or that they use several solutions, not all of them owned by their
unit, or both.
In many cases, the more quantitative questions, such as the number of FTEs devoted to data
curation, made it difficult to determine with precision the amount of effort libraries are expending on
data curation activities. Also, when querying the level of support provided by libraries (e.g., currently
providing or will provide in the near future, etc.), it appeared that responses were made relative to the
library’s overall resource pool. In other words, a small institution and a large institution might both have
responded at the same level of support, however, in absolute terms there may be a significant difference
between the two.
Additionally, analyzing the data and links provided by respondents to related resources indicates
that many institutions are providing curation activities only through their institutional repository, and are
therefore limited by its technical capabilities. However, other institutions provide additional curation and
review of the data files through staff-powered services.